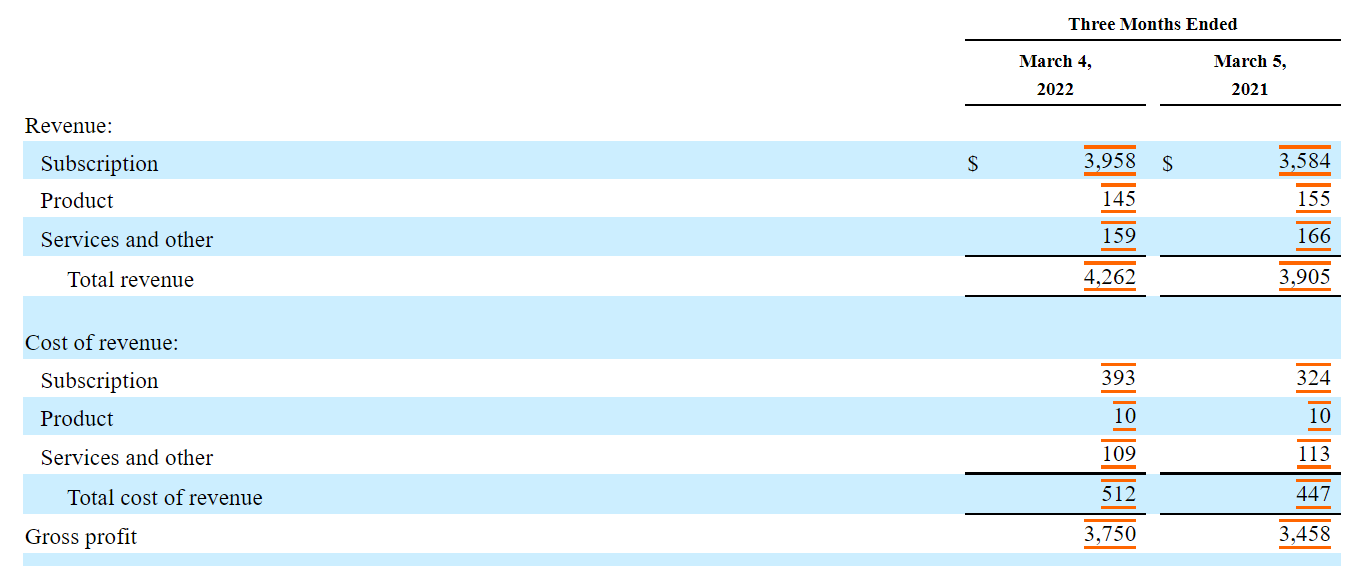Parsing data in Excel can be complicated, using a combination of functions ranging from LEFT, RIGHT, MID, and FIND. However, with the help of a few new functions that are available in Excel, the process is a whole lot easier for users. In this post, I’ll look at how you could parse out a date that is formatted as text using the new functions and comparing that with how you might have done it using the old functions.
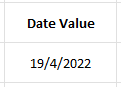
In this example, I’m going to try parse out the numbers I need to convert the following value, which is reading as text:
This date is April 19, 2022. But because my regional settings are set to month/day/year this value doesn’t compute properly since it would be looking for a 19th month.
Pulling the day value (data before the delimiter)
The old method
The first number in the date value above relates to the day of the month. Using the LEFT function in Excel, you could use something like this:
=LEFT(X,2)
Where X is the cell value. That will pull the first two characters in the string. But in some cases there might only be one day for the date. And for that reason, I’m not going to hardcode the number of characters. The best approach (under the old method) is by using the FIND function to locate where the delimiter (“/”) is. The more versatile formula would look as follows:
=LEFT(X,FIND("/",X,1)-1)
The new method
One of Excel’s new text functions is called TEXTBEFORE. And as the name suggests, it will extract all the text that comes before a delimiter. Without needing the FIND function, I can simply do this to extract the day value:
=TEXTBEFORE(X,"/")
Pulling the year value (data after the delimiter)
The old method
To grab the year in the date I could cheat and use the RIGHT function and just grab the last four numbers. But that wouldn’t be flexible enough in the event that I might have 2 digits instead of 4 as the year. This can get messy as now I have to use multiple FIND functions in order to determine the length. The key is to take the length of the function and subtract from that the position of the second delimiter. Here’s what that looks like:
=RIGHT(X,LEN(X)-FIND("/",X,FIND("/",X,1)+1))
The nested FIND functions can get a bit complicated. Here you’ll see even more efficiency with Excel’s new functions.
The new method
The TEXTAFTER function can greatly simplify this action because you can specify after which delimiter you want to pull the characters; there is no need to have nested functions with this:
=TEXTAFTER(X,"/",2)
In this formula, the characters after the second “/” will be extracted. Note: both the TEXTBEFORE and TEXTAFTER functions allow you to specify the instance of the delimiter (i.e. it doesn’t always need to be the first one).
Pulling the month value (data between delimiters)
The old method
The most challenging part of this process is undoubtedly to pull the data between delimiters. In this example, I’ll need to use the MID function and use nested FIND functions to determine the space in-between the delimiters. It’s an ugly formula if you don’t rely on hardcoding:
That’s four FIND functions in one formula. You can quickly see how parsing out this information can be a challenge. But with the new Excel functions, it’s much easier to do this.
The new method
There isn’t a new function that specifically pulls the values between delimiters. But by using both the TEXTAFTER and TEXTBEFORE functions, you can do exactly that. Let’s start with just grabbing everything after the first delimiter:
TEXTAFTER(X,"/")
This will give us the following result: 4/2022. Obviously that’s not what I want. But now, I can nest this within the TEXTBEFORE function, and grab the value before that other “/” with the following formula:
=TEXTBEFORE(TEXTAFTER(X,"/"),"/")
We are still dealing with a nested function here, but this is no doubt easier than all those FIND functions under the old method.
Using an array function
Another option that you can use is to extract all the values between the delimiters using the TEXTSPLIT function. Simply enter the following formula:
=TEXTSPLIT(X,"/")
Then the values will be extracted into three cells, one for the day, month, and year:
The benefit of this approach is you can quickly pull everything from the cell you’re parsing data from.
Regardless of which option you choose, Excel has given its users some new tools that can make the parsing much easier and less complicated than it was before.
If you liked this post on Excel’s New Text Functions, please give this site a like on Facebook and also be sure to check out some of the many templates that we have available for download. You can also follow us on Twitter and YouTube.
If you want to download a company’s financial statements or data, the easiest place is often straight from the source: the Securities & Exchange Commission (SEC). You can download financials in Excel format if there is an interactive option within the SEC filing, but that won’t give you all the tables contained in an earnings report. In this example, I’m going to use Adobe’s most recent earnings report to show you how to get a table into Excel
Downloading the data
Adobe’s earnings report is found here, with the following financials on page 4:
Copying it into Excel
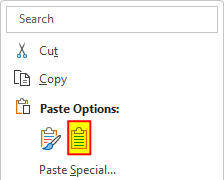
Copy the table and then go to paste it data into Excel. But when you right-click in Excel, make sure to select the option to paste it so it matches the formatting on the sheet, as shown below:
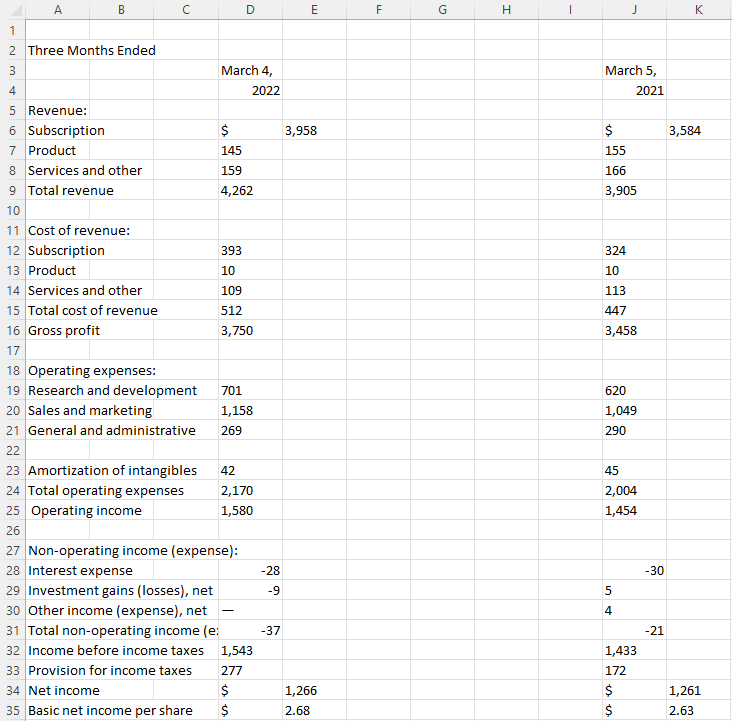
Now, the data pastes without any of the colors and formatting onto my Input sheet:
If when you paste it doesn’t show up like this and it looks like just a few lines, re-try copying the data. It may help not to include the header that says “three months ended” and simply start copying from the first line item (“revenue” in the above example”) to ensure that Excel picks it up as a table.
Formatting the data
It looks pretty good except that I have many extra columns. And numbers that have dollar signs have been pushed out by one column. What I will do here is create a template in a separate sheet that will automatically pull in what is needed. The new tab, called Output, will be where I create my formulas. My assumption is that the spacing will be consistent and that the current period values are in columns D and E, and the ones from the prior-year period are in columns J and K.
Starting in cell A1, I’ll create a simple formula that checks if the same value on the other sheet is blank. If it isn’t, then it will pull in the value, otherwise, it will remain blank:
=IF(Input!A1="","",Input!A1)
I will do the same thing for column B, except this time I am looking at values from the Input tab in column D. And I will need to adjust for if there is a $ sign. If there is, I need to pull the value from column E instead. Here’s what that formula looks like:
That gets me a bit closer to where I want to get to:
There are still a couple of issues. The first is that on row 30, there is a symbol that isn’t a dash that I need to remove. This is character code #151. And there’s also a trailing blank space behind the numbers that needs to be removed. This isn’t your ordinary blank space and it is character code #160. I need a couple of SUBSTITUTE functions to remove those character codes:
For character 151, I want to replace this with a 0 value since that’s what the symbol is in place of. Next, I need to convert these values to numbers. I can do this by multiplying them by a factor of 1. I’m going to use the IFERROR function as well so that in case it’s text, it will return the original value in column D. Here’s my completed formula:
Now, I can repeat this formula in the adjacent column. Except this time instead of referencing D and E, I’ll refer to columns J and K. Now, my output tab looks as follows, after applying some formatting to it:
This can be re-used over for other tables in an SEC report, as they generally follow the same pattern. For example, this is Adobe’s table showing sales by segment:
By dropping this into my Input tab, this is what my Outputnow shows:
All that I needed to do was to copy the formulas and just adjust the columns they referenced on the Inputtab. If you’d like to use the file I’ve created for your own use, you can download it for free, from here.
If you liked this post on How to Convert a Table From an SEC Report Into Excel, please give this site a like on Facebook and also be sure to check out some of the many templates that we have available for download. You can also follow us on Twitter and YouTube.
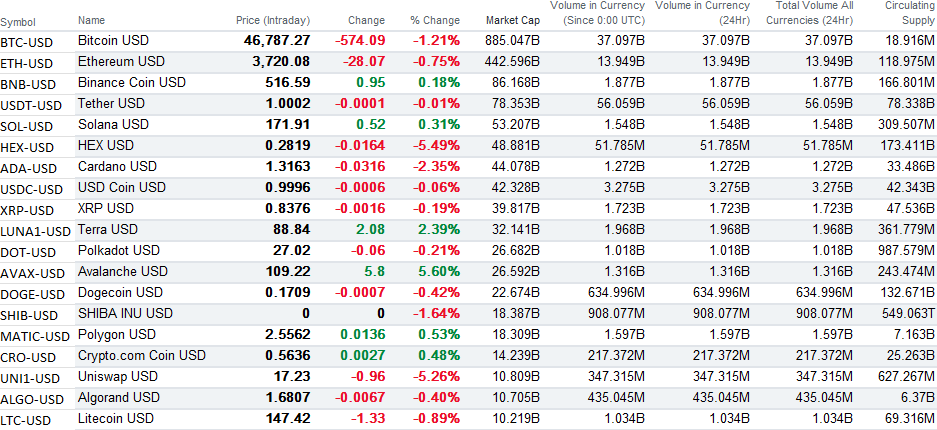
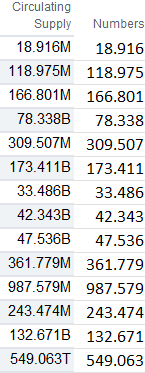
Oftentimes when you’re working with a large range of values, it can be useful to add letters such as ‘B’ to indicate billions or ‘M’ to show millions. It can save space and be easier to read without too many zeroes. But if you want to perform any analysis, you’ll need to ensure that you’re working with numbers, not string. Here’s a download from Yahoo Finance that shows cryptocurrencies by their market caps:
In this example, I’m going to extract the numbers from the circulating supply column, which contains millions, billions, and trillions.
Using the Substitute Function
If you want to remove the same text over and over again, an easy option for that is the SUBSTITUTE function. How it works is you select the string, the text you want to replace, and what you want to replace it with. Here’s how I would substitute out the ‘M’ for millions and replace it with a blank value in its place (assuming A1 was the cell that contained the text mixed in with a numerical value):
=SUBSTITUTE(A1,"M","")
The one limitation here is I’m only substituting out one letter. If I wanted to also replace the letter “B” then I would wrap the above formula inside of another SUBSTITUTE function, as such:
=SUBSTITUTE(SUBSTITUTE(A1,"M",""),"B","")
And, since there are also trillions in this data set, I will need to make another adjustment for the values containing the letter ‘T’ :
Now this formulas has gotten pretty lengthy. And as you can see, it can get even longer if there are more text values that you want to substitute out. The only thing left is to multiply this entire value by a value of 1 to convert the text into a number. My complete formula in this example, to pull out the numbers from text, is as follows:
Since you’re dealing with different units in this case, the one other thing you may want to do is add some logic to multiply it by a factor so you’re not mixing in millions with billions and trillions. However, with these now being numerical values, it’s possible to do with with just an IF statement.
Parsing Out Using Mid Functions
A more flexible way of pulling numbers out from text in this case is by using a combination of two functions — LEN and LEFT. With the LEFT function, you’re extracting out the characters at the start of a string. The key here is in knowing how many characters you want. This is where the LEN function comes in, as it counts the number of characters that are in a cell.
In the following formula, this would extract everything that’s in cell A1:
=LEFT(A1,LEN(A1))
This wouldn’t be a terribly useful formula since it would be the same as referencing A1. However, if I want to extract every character except the last one, as in the example above, I just need to adjust the second argument so that I deduct 1 from the length:
=LEFT(A1,LEN(A1)-1)
The only thing left to get the same results as in the example of the nested SUBSTITUTE functions is to just multiply this formula by 1. The advantage here is that I don’t have to worry about which specific letters to replace and I’m always going to be extracting all the characters except the last one.
There are more complicated examples of extracting numbers out of text and for those you might need to use the MID or RIGHT functions. Here’s an overview of how you can parse data out in Excel, which goes over more complicated examples than the ones noted here.
If you liked this post on How to Extract Numbers From a String of Text, please give this site a like on Facebook and also be sure to check out some of the many templates that we have available for download. You can also follow us on Twitter and YouTube.
Want to create a dashboard to track the stock market and the latest business-related news? Below, I’ll show you how you can create a stock market dashboard using Excel and Google Sheets to pull in all the data you’ll need. If you’d prefer to just download the file, you can do so here.
Step 1: Compiling the data
You can get stock prices into Excel using the STOCKHISTORY function. However, that isn’t available on older versions of Excel and it also doesn’t pull in the current day’s prices. Using Google Sheets can be more effective for this purpose. Plus, on there, I can pull in business-related news as well.
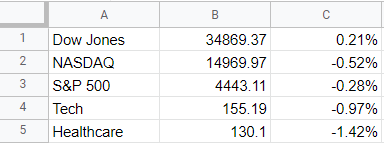
To start, I’m going to pull in values for the Dow Jones, Nasdaq, and S&P 500. I’ll also download the values of a couple of exchange-traded funds (ETFs) that track healthcare and tech stocks. To get the latest price, you can use the built-in GOOGLEFINANCE function that’s only available on Google Sheets. To get the latest value of the Dow Jones, the following formula will work:
=GOOGLEFINANCE(“.DJI”,”price”)
And to calculate the percentage change:
=GOOGLEFINANCE(“.DJI”,”changepct”)/100
For the Nasdaq, you’ll use “.IXIC” and for the S&P 500 the ticker is “.INX”
For the ETFs, since they aren’t indexes, there is no period beforehand and I reference XLK for tech and XLV for healthcare. In my Google Sheets file, I have a simple layout for the values and their changes that I will later pull into Power Query:
Next, I’ll also download the latest business-related news. Google Sheets has another unique function for this: IMPORTFEED. All you need to do is find an rss feed from a website that you want to pull information from. Not every website has an rss feed but what you can do is just do a Google search for the name of a source and ‘rss’ to see if you can find a link. There are three sources I’m going to use for this dashboard:
In Google Sheets, the top articles from each of those rss feeds will show up, including the title, URL, date created, and even a brief summary:
Now, it’s time to pull all this data into Excel.
Step 2: Loading the data into Excel using Power Query
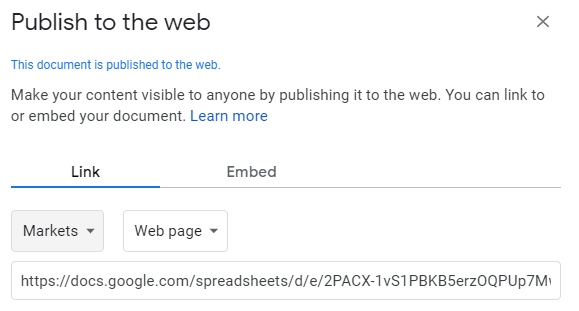
To import data from Google Sheets into Excel, you need to first share the sheet. While in Google Sheets, go into File -> Share -> Publish to web. Then, you’ll be prompted to select what you want to share. I’ll start with the Markets tab I created and then the News tab:
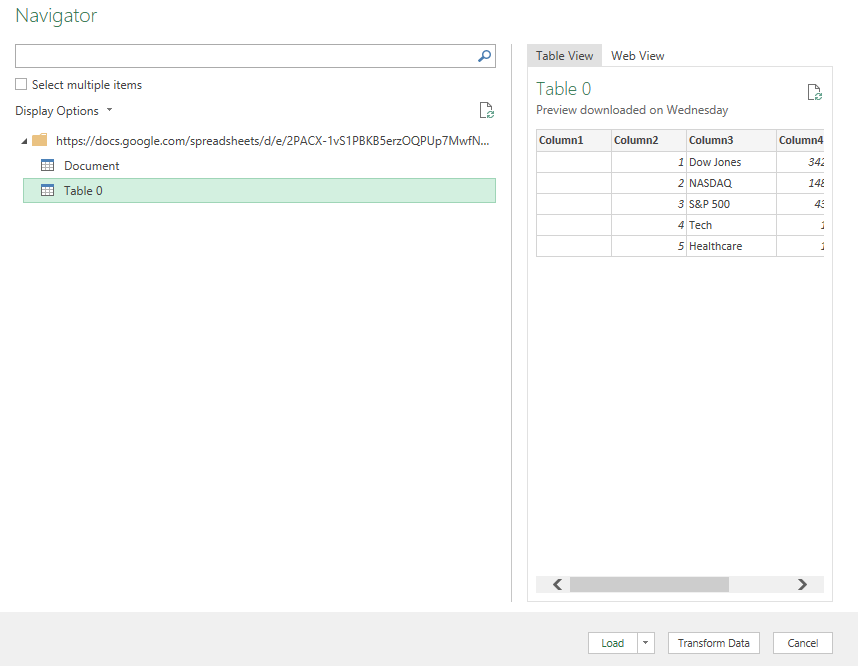
Copy this URL as you’ll need it to load the data into Power Query. While you’re back in Excel, go under the Data tab and click on the From Web button under the Get & Transform Data section. You’ll be prompted to enter a URL. This is where you’ll paste the link that you copied from Google Sheets:
On the next page, select Table 0 as where you want to extract data from. And if you want to do some cleanup (getting rid of extra columns), you can do so by clicking on the Transform Data button:
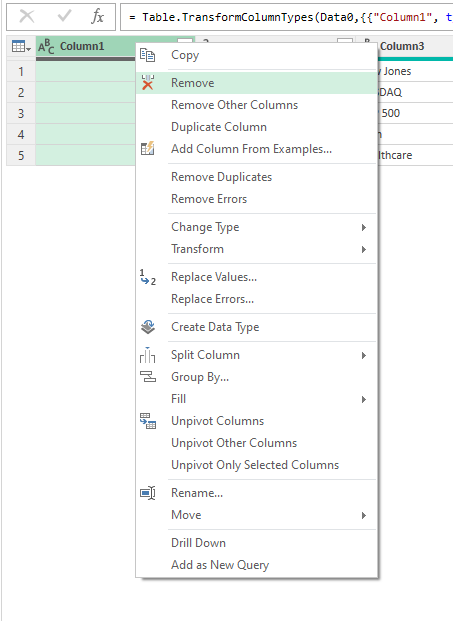
To remove any unneeded columns in Power Query, just right-click on a column header and click Remove:
Once you’re done, click on the button to Close & Load if you want the data to be loaded on a new sheet. If you want to control where it gets pasted, then use the drop down and select Close & Load To.
Repeat these steps for the other Google Sheets tab.
In addition, I’m also going to load data from a few other sources:
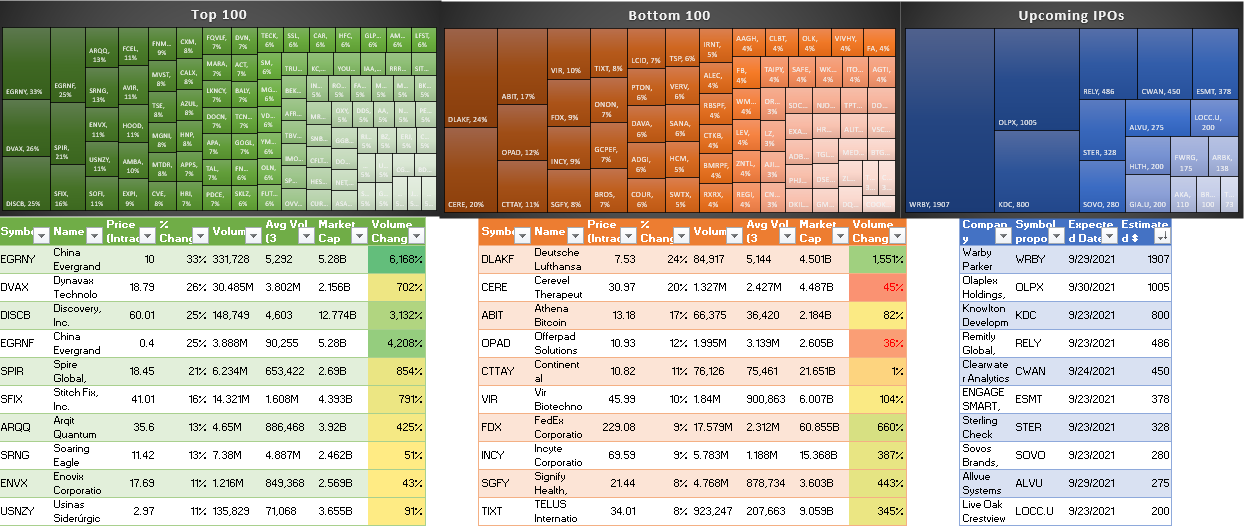
Top 100 Gainers on Yahoo Finance: https://finance.yahoo.com/gainers/?offset=0&count=100
Top 100 Losers on Yahoo Finance: https://finance.yahoo.com/losers?offset=0&count=100
Upcoming IPOs from IPOScoop: https://www.iposcoop.com/ipo-calendar/
The process for importing these links into the dashboard is the same as for Google Sheets. Go through Power Query, import from web, and paste in the URL plus make any formatting changes necessary. The next step involves putting all this data together in a dashboard.
Step 3: Creating the dashboard
In my spreadsheet, I’ve created two tabs: one that hold all my Power Query downloads (the ‘Data’ tab) and a ‘Dashboard’ tab for where all the information will be displayed.
To make the set up of the dashboard easy to manage, I’m going to change the column width to 10 for everything. To do that, press CTRL+A to select all the cells on the Dashboard tab, then right-click on any of the headers, and there you’ll be able to select column width.
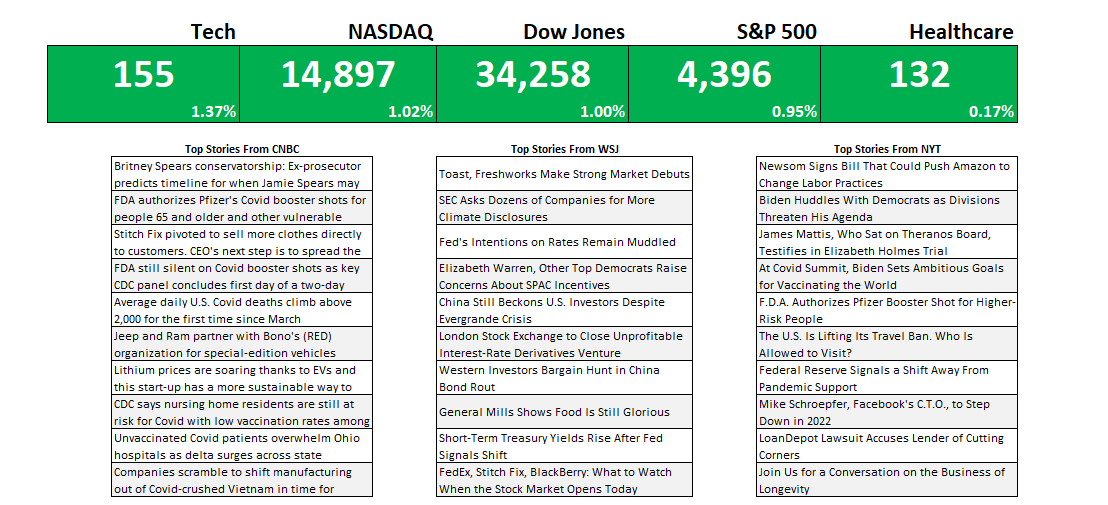
First up, I’m going to get the indexes and market indicators as a starting point. To do this, all I need to do is link to the values and the percentages for the S&P 500, Dow Jones, Nasdaq, Tech, and Healthcare tickers I imported from Google Sheets. By default, I’ll set the formatting for all the cells to be green:
To make this more dynamic, I will add some conditional formatting so that if the percentage change is negative, the corresponding cells will highlight in red. For this, I can select all the cells in green above and create a conditional formatting rule the starts with where the first percentage is (in my spreadsheet, it is cell E6):
=E$6<0
This is a simple rule but by not freezing the column (E) and freezing only the row (6), it can be applied to all the cells above. I can apply a red background color so that if any of the percentages are negative, the cells will highlight accordingly:
For the next part of the dashboard, I will copy over the news stories that were also downloaded from Google Sheets. This time, I’m going to use the HYPERLINK function so that I can not just link to the title but also create a clickable link that will allow me to open the story should I want to open it in my default browser. The function itself is simple and involves just two arguments, one for the actual URL and another for what the text should show up. Since it’s shorter, I’m going with the title. After applying some formatting and copying all three sources, this is what my dashboard looks like:
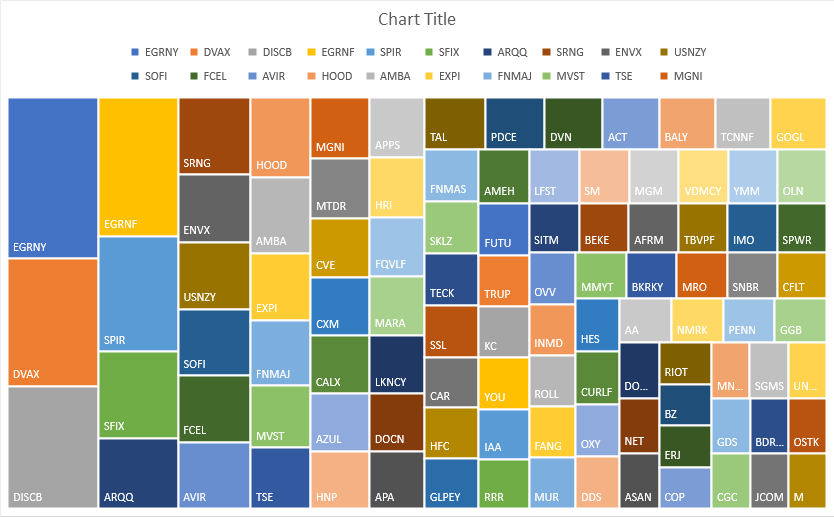
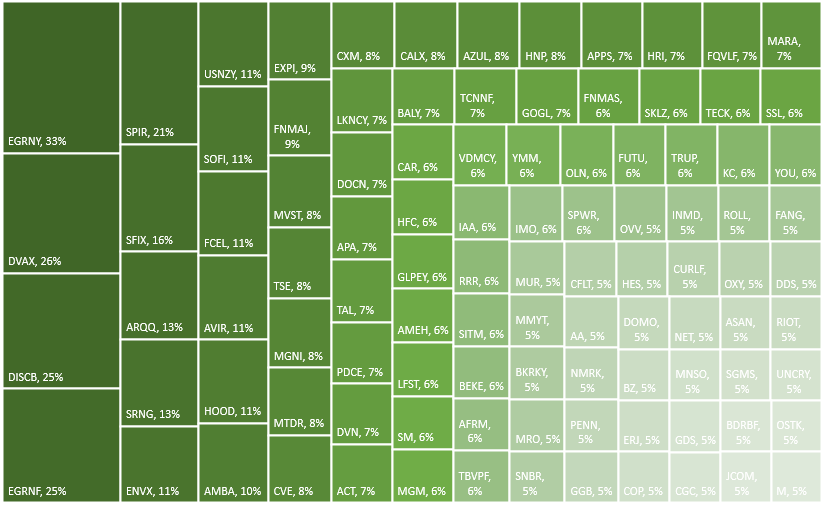
For the last part of the dashboard, I’m going to pull in the tables from the other data sources (top 100 gainers, losers, and upcoming IPOs). If these are on the Data tab, you can just cut and paste them onto the Dashboard tab. And for each one of the tables, I’m going to create a chart based on the symbol and the percent change.
To do this, select the Symbol column and the % Change columns. Then under the Insert tab in Excel, open up the charts and select Treemap. If you selected too many columns or didn’t specify which ones you wanted, you might get a different look. But if you only selected those two, you should see something like this:
Since the chart includes the symbols, the legend can be deleted. Also, I’m going to change the color scheme so that it goes from dark green to light green. This change can be made by clicking the Change Colors button next to the chart:
To add the percentage to each of the boxes, right-click on one of the ticker symbols and click Format Labels. Then, check off the box for value so that the percentages will also show up next to the symbols:
These steps can be repeated for the other charts. However, for the losers table, since the percentage change is negative, it needs to be flipped to positive first. To do that, that query needs to be edited. If you click on Queries & Connections section under the Data tab, you’ll see a list of all your queries. Click on the one that takes you to the top losers query. Right-click edit and Power Query will open up.
Once in Power Query, select the % Change column and under the Transform column at the top, click on the Standard drop down, which will show you all the different calculations you can apply:
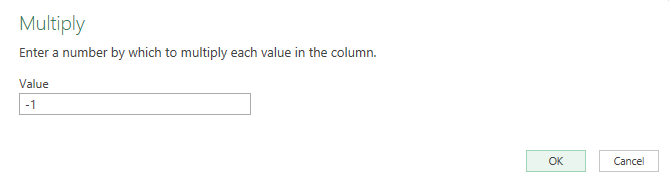
Click on Multiply and then for the value in the next box, enter -1. Pressing OK will then flip all the values to negatives.
Now, you can create the same Treemap chart for this table. For the IPOScoop download, the field I’m going to use is Est. $ Volume. This query will also need to be edited in order to use that field since it is text. Although it is a bit more complex since this field contains text and dollar signs, there’s a relatively easy way to parse out what you need.
In Power Query, select the column, and under the Add Column tab, click on the Column From Examples button (choose the option for From Selection):
That will create a new column:
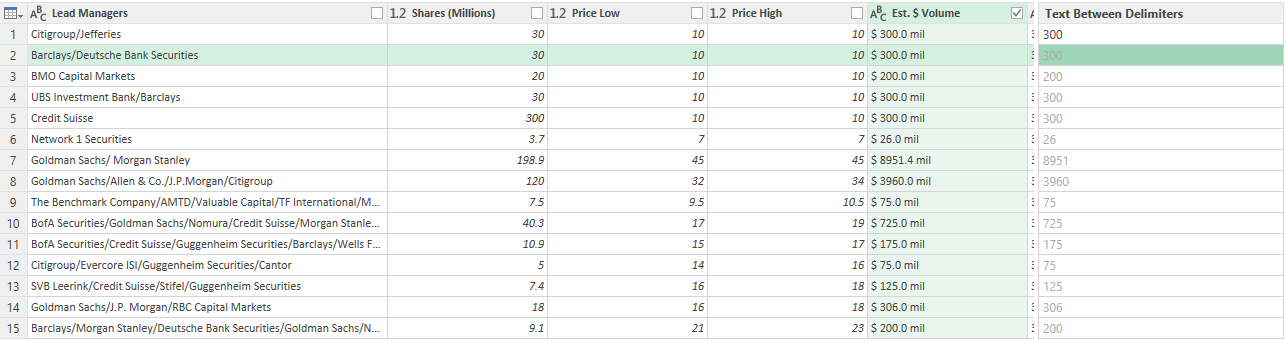
In Column1, I can enter the value that I want Power Query to extract. If I just enter a few values to show what I want (in this case, I only need to enter 300), Power Query fills in the rest, figuring out what I am trying to do. It’s an easy way to parse data in Power Query.
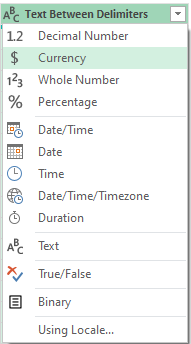
After creating the new column, I can change the format from text to currency by clicking on the ‘abc’ letters in the title:
Now that I have the column created, I can remove the original one and load the data back into Excel and proceed with making a Treemap for this chart using the symbol and the newly created column.
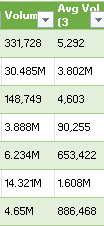
The last thing I’m going to do is create a new column to show the change in volume to determine how much more (or less) trading there was for each stock on the day compared to the average. This will compare the average three-month volume with the current day’s volume. The one complication is that some of the values contain letters:
To convert these values, it’s important to first parse out the letters. If a value doesn’t contain a letter, then it is in thousands. I’m going to set everything to millions. So if the value doesn’t contain a letter, it will be multiplied by 0.000001 to convert it into a fraction of a million. And if it contains a ‘B’, it will multiply by a factor of 1,000. Otherwise, the value will remain as is. Here’s how the first part of the formula will look like, which involves determining the multiplication factor:
Since the letter is always at the end of the string, just using the RIGHT function (which looks at the right-most string) will suffice. This result needs to be multiplied by the remaining value. That value can be extracted by using the SUBSTITUTE function which will replace one value with another:
SUBSTITUTE([@Volume],”B”,””)
In the above formula, the value of B will be replaced with an empty string. This is the same as simply removing the value. To ensure that any ‘M’s are also removed, I will embed this formula within another one that will substitute out those values:
SUBSTITUTE(SUBSTITUTE([@Volume],”B”,””),”M”,””)
I multiply this by the first part of the formula, and my numerator is as follows:
For the denominator, I’m going to use the exact same formula, except instead of the current volume, I’m going to use the field for the three-month average:
The -1 at the end is to put the change in a percentage of less than 100%.
Another step you might consider at this point to help identify these changes is to format these numbers so they are easier to read. You can use conditional formatting (color scales) to easily highlight the highs and lows. And if you want to format the percentages so that they show commas and negative percentages show up red, use the following in the custom number format:
#,##0%;[Red]#,##0%
The semi-colon before the [Red] separates out what the percentages should look like when they are positive (the part before the semi-colon) and what they should like when negative (the part that comes afterward). The [Red] text indicates the value should be in red text.
Here’s how this section looks as part of my dashboard:
And here’s a snapshot of the dashboard as a whole.
One thing to remember: if you want to update the queries and the dashboard, make sure you go under the Data tab and click the Refresh All button. Otherwise, your data may not be up to date.
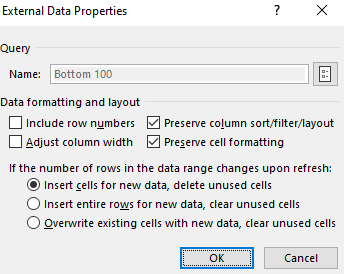
Also, to prevent your tables from stretching out when updating the queries, select each one of them and under the Table Design tab, click the Properties button (under the External Table Data section), where you should see this:
Make sure the Adjust column width checkbox is unticked. This will prevent your columns from stretching out and disrupting your layout.
If you liked this post on Creating a Stock Market Dashboard in Excel, please give this site a like on Facebook and also be sure to check out some of the many templates that we have available for download. You can also follow us on Twitter and YouTube.
In an old post, I went over how to parse data using various different functions. This time around, I’m going to show you how much easier it is do that in Power Query. If you’re not comfortable using LEN or MID functions, then this will make your life a whole lot easier. And to keep things simple, I’m going to use the same data set as I did in the previous post, which you can download from here.
Setting up the query
The first step involves copying the data from the webpage and then just pasting it into cell A1. With no adjustments, my data just contains the raw data:
The one thing I’m going to do is remove the blank rows just so that Excel recognizes the full data set without having to adjust it. I can remove the blank rows in Power Query, but I’m going to do it at this stage so I don’t need to worry about finding what row number I need the range to go down to. To remove blanks, I will select column A, press F5, special, blanks, and then right-click delete on one of the cells. Now that there are no gaps in my data, I can set up the query.
To do that, I’ll go into the Data tab, and in the Get & Transform Data section, click on the From Sheet button.
Excel should now autodetect the entire range. Click OK and the query will be created:
Right now, it looks the same as what it was before, except it’s in the Power Query window. Next, I’ll actually start making the transformations.
Parsing the data using delimiters
Just like in the older post, I am going to set up fields for Country, City, and Population. But this time, you won’t have to fumble around and worry about setting up complex formulas. In the Power Query Editor, I’ll select the Add Column tab. And in there, I’m going to select the Extract drop-down selection and choose Text Before Delimiter:
I’m going to use the colon (:) as the delimiter and then click OK
That nicely parses out the countries:
I can double-click on the header where it says Text Before Delimiter and change it say ‘Country’
Next, let’s parse out the City field. I need to make sure that Column1 remains selected. This time, I’m going to select Extract under the Add Column tab and then select Text Between Delimiters. I’m going to set my start delimiter as a colon. And the end delimiter will be the opening bracket:
And after re-naming the field to City, this is why my Power Query Editor looks like:
The last column to parse out is the Population. For this, I’m going to follow a similar step as above except I’m going to extract the text within the brackets. But in some instances, there is data within brackets that doesn’t relate to the population. But one consistency is that the population always comes at the end. So in this case, I’m going to use the Advanced options and specify that I want to start searching from the end of the string. I have left the other options the same:
Now, my fields look pretty good:
The one thing I still need to do is remove the headers for the different letters. Since there is nothing in brackets, I can filter for any blank value in the City field. To do, this, I will click on the drop-down arrow for that field and select the option to Remove Empty:
Now, the data looks good and ready to import back into the worksheet:
I technically don’t need that first column anymore. It’s done its job and one of the great things about Power Query is I can delete it, and it won’t impact everything else I’ve done. I’m going to right-click and delete that column so that all I’m left with are the fields I actually need:
All that’s left now is to load the data into the spreadsheet. To do this, click on the Close & Load button in the top-left corner. It will now put that into a new tab by default:
And just like that, you’ve parsed the data without having to go a painstaking effort of figuring out the correct formulas. But as easy as this was, there is an even easier way of parsing the data out (most of the time).
Parsing the data using examples
I’m going to re-do the previous step, this time taking a different approach, without the use of delimiters. This time, I’m going to the Add Column tab and select the Column From Examples button. This will generate another column on the right-hand-side:
What I’m going to do in Column2 is give Power Query some examples of what I want this field to contain. Since it is the Country field, I’m going to start by typing out a country name. Even after just entering the first one, Power Query has figured out the pattern and does the rest for me:
You’ll notice at the top it has the Text Before Delimiter which is what I used when I did this manually. The less complicated the data, the quicker and easier it will be for Power Query to predict what I’m trying to do.
I’ll repeat the step for the City field. This time when I enter just one value, it hasn’t figured out the rest of the values:
Instead of La Paz at the bottom of the above screenshot, it only pulls ‘La’ and so what I will do is correct that entry manually. Upon doing that it updates the calculations, but they still aren’t quite right. For Bosnia and Herzegovina, it is including part of the country name:
I will manually update that value to just enter Sarajevo, and once I do that it now looks correct:
And if I look at the formula that it has generate, it now is the same as what I did manually with selecting the delimiters:
The last column, Population, was the most challenging to set up because I needed to use the Advanced settings. Let’s see how well Power Query is able to extract this one using examples. Again, I’ll start with entering in the first value:
It doesn’t look too bad except for La Paz, it pulls in ‘seat of government’ which is in brackets, as opposed to the population. I’ll manually correct this one, and upon doing so this is what my column looks like:
Now the problem is the n/a values aren’t picking up correctly. Once I correct them, the column looks to be correct, except for Delhi:
After making a few more adjustments, the column looks to be correct:
One of the challenges with doing it this way is if a field isn’t easy to predict for Power Query, it may take some manual entry before it is able to get it just right. And even then, you may not be certain that you’ve accounted for all the possible variations. While this method can make it really easy for simple data parsing, for more advanced ones you will likely want to familiarize yourself with how to use the different Extract options.
If you liked this post on How to Parse Data in Excel Using Power Query, please give this site a like on Facebook and also be sure to check out some of the many templates that we have available for download. You can also follow us on Twitter and YouTube.
If you’ve inherited or downloaded a data set, you know that sometimes you’ll need to combine data together to make it in the format that you want. A good example is a list of addresses where you may have the street information in one column and the zip or postal codes in another column. To get all the information in one cell would require combining the information. Below, I’ll show you multiples ways of how you can combine two or more columns in Excel.
My data set for this example includes some sample address information on Sam’s Club and Walmart locations in the U.S. :
Using the ampersand to combine columns together
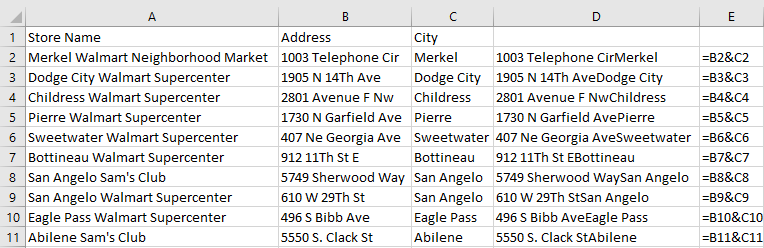
The easiest way is to join the cells through a simple formula. The easiest way to do so is by using the ampersand (&). In column D below, I’ve joined the cells and in column E is the formula that I’ve used:
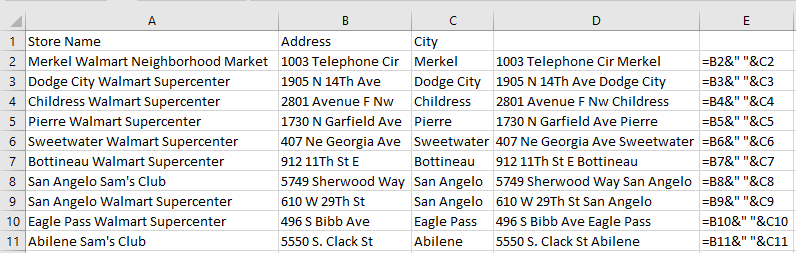
This gets the job done but you’ll notice a small issue: there isn’t a space between the information. that makes the data a bit messy and it’s probably not what you want. But it’s an easy fix. It can be addressed by adding another ampersand between the cells and add open quotes ” ” to add a space. This is how my spreadsheet looks after I’ve made those changes:
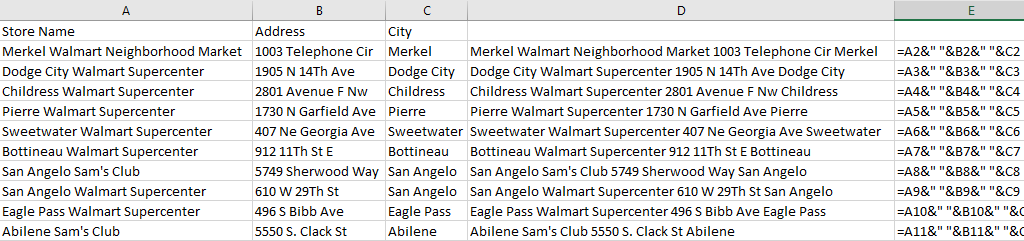
This can be expanded to more than just two columns. If I wanted to add the store name field (column A) into the mix, then it’s just simple as adding another ampersand for the field and another one for another extra space. Here’s how the data looks like all three columns joined together:
This can start to become a bit cumbersome as you add more fields into one cell. An alternative way that you may find easier if you’re working with several columns is using the CONCATENATE function.
Using the CONCATENATE function
The CONCATENATE function works very similar to how the ampersand. However, it’s a bit cleaner in that you don’t have several ampersands in your formula. If you wanted to group cells A2, B2, and C2, your formula would look like this:
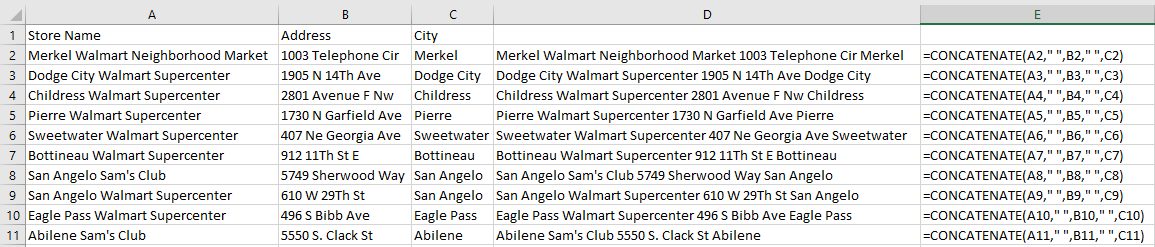
=CONCATENATE(A2,B2,C2)
If you want a space to be included between each of those fields, then it looks like this:
=CONCATENATE(A2,” “,B2,” “,C2)
Here’s how that would look if I applied it to my existing data set:
You can use commas to separate the data if you prefer and in that case, you would just use “,” instead of an empty quote. You can also add extra spaces in between quotes to space out your data even further.
But whether you choose to use the ampersand or the CONCATENATE function just comes down to preference. Either approach can get the job done.
If you liked this post on how to combine cells in excel, please give this site a like on Facebook and also be sure to check out some of the many templates that we have available for download. You can also follow us on Twitter and YouTube.
If your data contains date and time, and you only need the former, there are ways for you to remove time from the excel date. The first step, however, is in determining whether your data is in date format or whether the information is stored as text. Depending on which one it is, it will change how you will need to manipulate the data.
You can use the TYPE function to determine whether your data is in text or numeric format. The function evaluates a value and if it is numeric it will return 1 and if it is text the result will be 2. That will determine which path you need to focus on: converting a text date or just pulling the date values that you need. The latter is the easier of the two approaches.
Removing time from a date value
If the data is in date format, then it’s as easy as using the DATE function to pull out the fields you need. Let’s start with a date that shows the following:
2020-02-29 12:00:00 PM
It has more detail than we need with the time in there but it also has everything that’s needed—year, month, and day. The easiest way to pull out the date is using a formula as follows (where A1 is where the original data is):
=DATE(YEAR(A1),MONTH(A1),DAY(A1))
The DATE function takes three arguments: year, month, and day. By pulling these values out from the cell that has the time, we’re effectively creating a new value that has everything except the time. Now, if you don’t want this to remain a formula what you can do is copy the cell with the date and not the time, and paste it as values. Now, you’re left with hard-coded date values that do not contain the time.
As mentioned, this is the easy part of the process. The more difficult one is if your date is stored as text and where the DATE function results in an error if you try the above calculation. Let’s take a look at how to remove time from an Excel date when it’s in text format.
How to extract the date from a text field
If the same value above was stored as text, the formula involving the DATE function would result in an error. To pull the values that are needed to arrive at a proper date value, we’ll need to parse the data. Parsing can be a bit complicated but when you’re dealing with text, it’s the only way around getting the data you need.
In the above example, the date fields were separated by hyphens but it could be that slashes are used as well. Ultimately, it doesn’t matter, so long as there is some pattern that separates the month, day, and year fields. We will still use the DATE function. But in order to put the correct values in, pulling out the key information is going to be the challenging part.
Let’s start with pulling out the month, since in a month-day-year format, it’ll be the first value and thus, the easiest to extract. Here’s how the formula to pull the month would look, again, assuming A1 is where the data is:
=LEFT(A1,FIND(“-“,A1,1)-1)
Since the month is the first value, we use the LEFT function to pull the characters at the beginning of the cell. A1 is the cell we’re looking at, and the second argument is the length of the string to pull. Here, we’re looking for the dash(-) within the cell and subtracting one character so that the dash itself isn’t included in the extraction. This formula would produce a value of ’02’ and correctly return the month value.
To get the day is a bit trickier since it’s between dashes. It’s still possible to extract it but the formula is a bit more complex and requires using the MID function. Here’s the function with just the first two arguments filled in:
=MID(A1,FIND(“-“, A1 )+1,
The first part of the formula specifies the starting point. For here, we’re again using cell A1 but this time we’re looking for the dash using the FIND function to indicate where the second value begins. We add one to this value to ensure that we aren’t starting at the dash. Here’s what the next argument looks like, for the length of the value:
Here what we’re doing is using the FIND function to search for the dash but this time we aren’t starting from the first position but are starting from where the first dash was found, and adding a one to that. Then we subtract where the first dash was found, and the difference is the length of the string. It’s a complicated, nested function but it does what we need it to do. The completed formula for the day looks as follows:
The last part is to extract the year. And because this comes after the second dash, we’re going to need to nest two FIND functions, not just one. You could try and always start from a certain number, for example, the seventh character if your date format will always by mm-dd-yyyy. However, using the FIND function ensures you aren’t taking any assumptions (e.g. they may be leading spaces). I also avoid hardcoding numbers in formulas whenever possible. Here is the formula that remains for the year function:
The nested FIND functions are needed to ensure that I’m starting to search for the dash after the second instance was found. I use the number four for the last argument because rather than making this formula even more complicated, I figure the year will either be two characters or four, and it won’t deviate. If your data contains two characters for the year, then you can just change the final argument accordingly.
That leaves us with this long formula to extract the date for the mm-dd-yyyy:
It’s a complicated one so it may be easier to just copy and paste it rather than trying to reconstruct it yourself. If your original date is in dd-mm-yyyy format, here is a formula for that:
This just involves flpping around the formulas to grab the month and day. If your dates use “/” instead of “-“, then you can just to a find and replace in the formulas above to replace all the “-” with “/” or whatever else your system may use. Regardless how the data is separated, you can adapt the formula to how your data looks.
As you can see, having your data in the right format can make this process a whole lot easier. It’s once you get into text that it becomes much more challenging in pulling the date out. And again, once you’ve got the data you want, copying and pasting as values will ensure you don’t have to keep both the old and new data together.
If you liked this post on how to remove time from Excel date, please give this site a like on Facebook and also be sure to check out some of the many templates that we have available for download. You can also follow us on Twitter and YouTube.
If you need to keep track of time entries, whether for a timesheet or some other purposes, it’s important you know how to calculate time differences in Excel, and that’s what I’ll show you how to do in this post. If you’re just looking for the difference in dates, including months, days, or years, then refer to this post. But if you need time differences, keep reading.
Entering time correctly
In order for the difference in time to be calculated correctly, it should ideally be entered in the right format to start with. Let’s use the example calculating the hours worked for a regular 9-to-5 shift.
You can use a 24-hour clock or AM/PM to enter time. If you’re using AM/PM, then you’ll want to make sure you enter a space between the time and the AM/PM indicator. For example: 9:00 AM rather than 9:00AM.
If you enter it correctly, then the value you just entered should align to the right. This means that Excel has interpreted it as time. You can also tell because in Excel it will show as 9:00:00 AM in the cell details. Normally, you aren’t going to enter seconds but Excel will track those extra zeroes anyway.
If you were to just enter 9AM then you’ll notice after hitting enter that nothing happens and Excel doesn’t align it to the right side of the cell. This means that what you’ve entered Excel is reading as text.
That is a problem because if you want to calculate the time difference correctly, it’ll get a whole lot more complex and require using IF and MID functions. It’s not impossible (and I’ll show you how to do so later on), but it will make it a lot more complicated.
Calculating the time difference
Now that you’ve made sure that the time entries are entered correctly, it’s time to show you how to calculate time difference in Excel. Here’s how it looks if I just take the end time and subtract the start time:
If you’re using the 24-hour clock then it looks okay. However, the calculations are still reading in the time format and while that may work okay for the 24-hour clock, it’s going to cause an issue for the AM/PM. So let’s change the format using the comma style so it doesn’t read like a date. Then, the data looks as follows:
This might seem even more confusing until you realize what Excel is doing. It’s assigning a value between 0 and 1 for the time of day. The value of 0.33 indicates that the time is one-third of the day, which is what an eight-hour shift would be since 8/24 is the same as 1/3.
However, using 0.33 isn’t going to be too helpful if you need hours to be able to track how much someone should earn for that shift. To solve this, simply multiply the time difference by 24. Then, your time difference looks as follows:
Now you see the eight hours that you may have first expected to see when calculating the difference between these times. Since it’s now reading as a number, you can multiply this by an hourly rate and arrive at the pay that is owing for the shift.
If you’re not looking for hours and just want the total minutes, then all you need to do is just multiply by a factor of 60 to convert the eight hours into 480 minutes.
Calculating hours worked when someone works the night shift
The above calculations work well if someone is working within the same day, but if someone starts at 9:00 PM and ends at 5:00 AM the next day, it’s not going to calculate properly if you simply take the difference between the numbers. In fact, the number would come out negative:
That’s obviously not what you’ll want. To account for this, you’ll need to add an IF statement into our formula. The IF function should look at whether the end time is earlier than the start time. If it is, you’ll want to add 1 to the calculation. Here’s how the formula for the difference calculation would look like:
I include the 24 in the calculation so that I don’t need to use an extra cell to convert the difference into hours. All the formula is doing is looking at if the end time is before the start time, and if it is, add a 1 to the end time before subtracting the start time from it. This method will work whether you’re using a 24-hour clock or the AM/PM format:
This method will work even if someone works a 16-hour shift:
Knowing how to calculate time difference in Excel isn’t difficult, and the key points to remember are as follows:
Ensure the time is entered correctly, and
Multiply the difference between the times by a factor of 24 for hours and another factor of 60 if you only want minutes.
Calculating time difference in Excel when the data is in text
If you need to know how to calculate time difference in Excel and you don’t have the luxury of the data being in the right format, the good news is it’s still possible to do so.
For instance, what if you want to enter the entire start and end times within one cell. In that case, you’re always going to be running into this situation. Suppose someone enters the following value into a cell: 9:00 AM-5:00 PM.
The format would be correct if there weren’t multiple times in that cell, which ensures it will read as text. That’s where you’ll need to use some data manipulation that involves using the MID function.
Let’s start by pulling the start time. For this, we’ll grab the numbers that come before “AM” but because it doesn’t matter whether it’s AM or PM, we’ll search for the letter “M” on its own:
=MID(A1,1,FIND(“M”,A1,1))
Here’s a breakdown of the formula:
Argument 1: A1 is the cell we’re looking at.
Argument 2: Start pulling from the first character.
Argument 3: The length of the text goes up until the letter “M” is found.
The formula will yield a result of 9:00 AM. However, you’ll still need to convert this into a number and you can do this by multiplying the result by 1 or putting it inside the TIMEVALUE formula:
=TIMEVALUE(MID(A1,1,FIND(“M”,A1,1)))
This will now give us a value of 0.375 and it can be used for the calculation. Next up, we’ll calculate the ending time. To do this, we’ll again use the MID function but the key is to start pulling the data after the dash (-) sign:
=MID(A1,FIND(“-“,A1,1)+1,LEN(A1))
This one is a bit more complicated, but let’s look at the different arguments again:
Argument 1: Still looking at cell A1.
Argument 2: Use the FIND function to get to the position where the dash (-) is at and then add a 1 onto that to ensure we’re starting from where the number begins and not the dash (-).
Argument 3: Even though you don’t need the total length of the string, you can use the LEN function to ensure the formula get everything that comes after the dash (-).
Doing this will give us a result of 5:00 PM and by again adding the TIMEVALUE function into it, it will give us a result of 0.7083
=TIMEVALUE(MID(A1,FIND(“-“,A1,1)+1,LEN(A1)))
You can now combine these formulas into one to do the calculation with text:
This will result in 0.33 for the time difference, which is the correct result. However, with shifts that stretch into the following day, you’ll again run into the issue of how to deal with calculating time. If you don’t have night shifts to worry about, you can stop here.
But if you need to factor them in, then the easiest way to do so is using the AND and IF functions. We’ll want to look at whether the last two characters end in “AM” while also looking at whether “PM” is in the text:
The first formula inside the AND function looks at the last two characters in the text to see if they equal “AM”
The second function looks for the characters “PM” anywhere in the cell. If it’s not found it will result in an error, that is why the formula begins with NOT and ISERRROR; you’ll want to add a 1 if it isn’t causing an error and “PM” is found.
If both of the above conditions are met, a value of 1 will be returned. Otherwise it will result in 0. This can now be added to the earlier time calculation formula, added to the end time.
Here’s how the complete formula will look like after adjusting the end time in case there’s a cross over from PM into AM:
It’s a messy formula but it is only adding the 1 to the end time if it’s a PM start time and ends in the AM. The only thing left would be to multiply this all by 24 to get the entire shift total in hours:
The key thing to note is for this formula to work it’s important to leave a space between AM and PM. For example, if I were to just enter 9:00AM, Excel wouldn’t read that properly and it would result in an error. By leaving a space, it helps with parsing the data out, otherwise the formula would need to be even more complex. If it isn’t in that format, it’s preferable to first clean up the data as opposed to building a very complicated, nested formula using IFs and MIDs.
The above example goes over a few scenarios and obviously you can adjust the MID and other functions as needed based on how your inputs look. Pulling date calculations out from text is possible, it’s just no very pretty.
If you liked this post on how to calculate time difference in Excel, please give this site a like on Facebook and also be sure to check out some of the many templates that we have available for download. You can also follow us on Twitter and YouTube.
If you deal with credit card transactions a lot then you know that trying to get the vendor name out of the descriptions can be challenging to say the least. Companies can sometimes cram a lot of information into their doing business as (DBA) name that can show up on your statement. Information such as store number or even the contact phone number can show up in there. The problem is that when trying parse this data in Excel, it can get a little messy.
However, I’ll show you how you can pull valuable information out of the data just by using a formula. Because there are no rules around DBA names, there’s no way that will work 100% as ultimately it’s up to the company to determine how the data shows up.
Quick side note – I’ve seen some interesting variations when it comes to DBA names, especially on corporate cards when some less-than-savory adult establishments tried to decoy themselves as restaurants. For example, it took some digging when I was examining expense reports to find out that a DBA name of Glenarm Restaurant in Denver was actually a strip club, the Diamond Cabaret. So yes, there’s not even a guarantee that the DBA name will reflect what’s even the name of the company. It’s a clever (and sleazy) way for an establishment to disguise itself as something else, especially say if someone’s spouse were to catch glimpse of their credit card statement…
…And we’re back from commercial break.
So as you can see from the above example, there’s an inherent limitation when it comes to using DBA names. However, we can still find ways to pull useful data from the majority of names that have at least predictable patterns and honest names in their descriptions. Here are some items from my latest credit card statement:
When it comes to parsing data it’s all about patterns. And there are a few things that stand out from the above list.
The vendor name shows up at the beginning of the description.
For those that have a store #, anything to the right of it is store and location level data and unnecessary for pulling the vendor name.
For those that don’t have a # we can usually just take the first couple of words as in most cases a vendor name won’t go to three words, and at the very least ,two should be enough for us to figure out who the vendor is.
So what we’ll have to do now is to build a formula that accounts for these assumptions to effectively create a formula that will parse it out.
First, let’s create a formula that will pull everything up until the # sign. A good test will be the fast food transactions, which typically have store numbers. To do this I’ll rely on the MID function as well as the FIND function. Here’s how it looks like:
=TRIM(MID(B1,1,FIND(“#”,B1,1)-1))
In the above example, assume that column B is where the data is stored in. Since the name begins in the first position, the second argument is the number 1, and the third argument is up until where the # sign is and that’s the point of the find function. A -1 is deducted to ensure the # sign itself isn’t included. That way, the description will grab everything up to just before the # sign. To clear off any trailing space, we can also the TRIM function to make sure no extra spaces are included in the results.
That takes care of the descriptions that have a # sign, but for the ones that don’t, it’ll result in an error. This is where we’ll want to create another formula to pull the first two words. The formula for that looks like this:
=MID(B1,1,FIND(” “,B1,1+FIND(” “,B1,1))-1)
This is a bit more complicated of a formula because it’s looking for the second space within the string. To do that, I have to the second FIND function picking up where the first one left off at is it starts looking for the blank cell after the first one is found (this is why the starting point is 1+ where the first blank cell is found). For the length of the string, here too we’ll want to add a -1 to the end to make sure that the blank space isn’t picked up.
So now we’ve got two formulas, and the next step is going to be to combine them into one. To do that, I’ll add an IF function to say if there is a # sign found within the text, to use the # sign formula, otherwise to use the two word formula. The IF condition looks like this:
=IF(ISNUMBER(FIND(“#”,B1,1)),1,0)
I will now replace the 1 or true argument with the # formula, and the 0 with the two word formula. And here’s what we’ve got so far:
The one change I made was I moved the TRIM function at the beginning of the formula to include all the arguments.
Lastly, I’ll want a catch all just in case I run into a DBA name that has fewer than two spaces in its name and no # signs. To do this, I’ll just use an IFERROR function at the beginning and the default will then be to just use the entire cell’s contents:
It’s gotten to be a pretty big formula but this will do a pretty good job of getting the vendor names pretty well. Like I mentioned, it won’t be perfect, but at the very least it’ll do a good job of pulling out most of the vendor information that you need.
In my example, the DBA name was in cell B1, but you can just do a quick find and replace on this formula to adapt to your data set and then just copy the formula as you need it.
Here’s how my data looked like using this formula:
Looks like a pretty good job by the looks of it. At the very least, the vast majority look to be unique enough in case I wanted to group them.
This is part of an upcoming template that I’m working on to help quickly analyze expenses, and a key part of that is being able to efficiently pull out vendor data from your statement.
If you have any questions, comments or suggestions please let me know.
If you liked this post on How to Parse Data in Excel: DBA Names, please give this site a like on Facebook and also be sure to check out some of the many templates that we have available for download. You can also follow us on Twitter and YouTube.
In a previous post I have gone over how to use LEFT and MID functions for parsing data, but in this post, I’ll go through a specific example from start to finish.
I am going to pull my data from the citymayors website, url as follows:
http://www.citymayors.com/features/capitals.html
The data on this page looks like this:
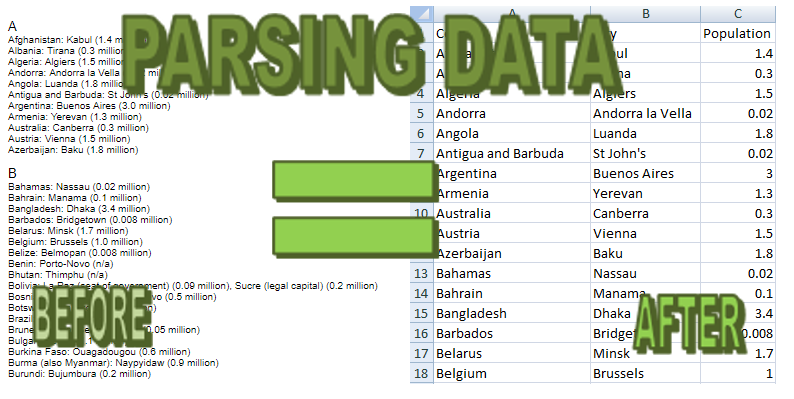
At first glance, this isn’t the most useful data that you can paste into an Excel spreadsheet but I’ll show you how it can be made more usable. First off I will copy the entire data set into a spreadsheet.
It copies in much the same as how it looked on the webpage. The problem is it is not in a format that you can do any analysis on. The structure it currently follows is Country: City (population). The more consistent the data is, the easier it is to pull the information out. In this sample, there are some inconsistencies but for the most part, it follows a logical pattern.
I am going to make the following columns: Country, City, and Population.
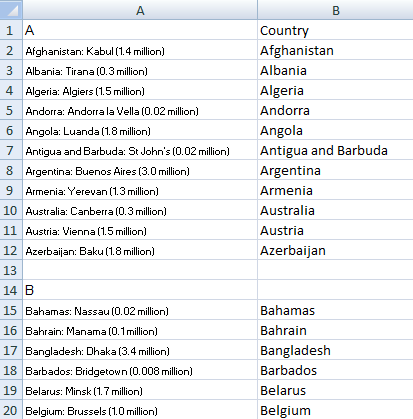
I’ll start with the Country column. For this field, I can use the LEFT function. However, the country names range in length so I can’t simply take the first x amount of characters. Instead, I have to look at where the colon shows up and stop one character before that.
I am going to start will cell B2 to analyze cell A2. In order to find the colon, I can simply use the FIND function. The formula for this will look as follows:
=FIND(“:”,A2,1)
I insert this formula into the LEFT function so that I get the following
=LEFT(A2,FIND(“:”,A2,1)-1)
What this formula does is look at cell A2, and pull characters until one before the colon (since I don’t want to actually include the colon). I will make one additional adjustment to avoid errors and that is if the cell in A2 is fewer than two characters it will return a blank (rather than an error since it would not find a colon). The formula to check for a length greater than two characters is this:
LEN(A2)>2
Inserted into my earlier formula:
=IF(LEN(A2)>2,LEFT(A2,FIND(“:”,A2,1)-1),””)
This qualifies the cell first by saying only if it is more than two characters long will my formula try to pull data out, otherwise, it will leave it as blank (“”). I will copy this formula all the way down my country field. This is what my spreadsheet looks like now:
Next up is the City field. This one is going to be a bit more difficult because I can’t start from the left and have to use the MID function where I will need to search for both the colon (my starting point) as well as the bracket that starts the population field (my ending point). In the MID function, I need to specify the start and endpoint, whereas with the LEFT function it started from the first character in the cell.
The first formula I need to make is to get my starting point. But I’ve already done that in the country field, I can just copy the FIND formula from earlier:
FIND(“:”,A2,1)
In this case, I will want to add +2 to the end of it so that it skips over the blank space after the colon and starts at the first character of the city name. My formula currently looks like this:
=MID(A2,FIND(“:”,A2,1)+2
Next, I need to find the endpoint, and similarly, I can use the FIND function to find the opening of the parentheses. The formula for this is similar to my earlier one:
=FIND(“(“,A2,1)
I will want to subtract two characters from this so that I do not include the open parenthesis character or the empty space before it. If I insert this formula into the MID function I now have the following:
=MID(A2,FIND(“:”,A2,1)+2,FIND(“(“,A2,1)-2
The problem with this is finding the ( character does not tell me how long the city field is. To get the actual length of the field, I need to subtract the starting point of the field, which is again using the earlier formula to find the colon. My adjusted formula looks like this:
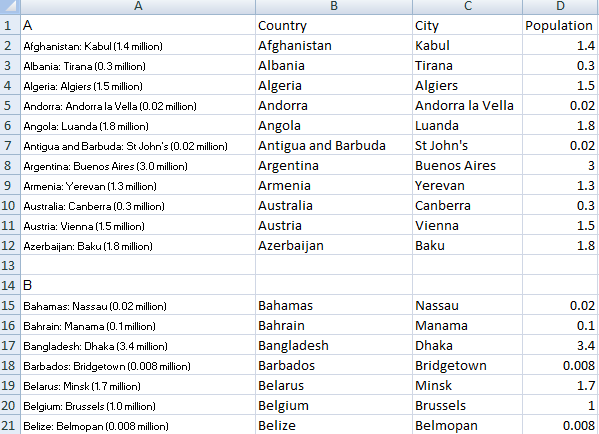
If I copy this formula down my spreadsheet now looks like this:
Next is the population field. Again I will use the MID function and I can use the endpoint of the city field as the starting point for my population field. I am only going to extract the numbers because numbers with text are not useful for analysis. If I wanted to I could pull the million text into another column and then could adjust the numbers accordingly. However, in this instance, it looks like all the figures are in millions so it is not necessary.
My formula starts as follows with the MID function and the previous formula to find the ( character:
=MID(A2,FIND(“(“,A2,1)+1
I added the +1 again so that it starts from the number rather than the ( itself. Next, I need to find the length so I need an endpoint for which I can use the FIND function again. This time I can just look for the empty space that comes after the number. So far I have the following:
=MID(A2,FIND(“(“,A2,1)+1,FIND(” “,A2,1)
The ” ” indicates a blank space. The problem here is I cannot start from the first character because it will find the first space. If the country has a space it will return a value from there, and if not there it will pull the space that comes right after the colon. What I need to do is change the value of 1 to where the ( is found. The updated formula:
This will now make sure it retrieves the first space after the ( character, which is what I want. I could have made it simpler and just looked for the word ‘million’ but that would not work for instances where the word did not show up (and I also wanted to show a more complicated example). Next, I need to subtract the starting point so that the length is correctly calculated:
I deducted one at the end because I did not want to include the space after the number. However, there is still one problem. Even though I extracted a number it is still text. I can convert it to a number simply by multiplying the result by one:
Now the number aligns to the right of the cell, indicating it is a number rather than text (which aligns to the left). I will add my qualifier for the length of the cell:
Unfortunately the data set is not perfect and in some cases there are text in parentheses so I would want to correct any of those cells – which should be easy to find since they result in errors. Alternatively, I could in the meantime use an IFERROR function to make any errors result in a 0 value:
Copying the formula to all the cells my spreadsheet now looks like this:
Using the IFERROR allows you to make the data usable for data analysis. And at the same time because you wouldn’t expect a population to be 0, you can still easily find error cells.
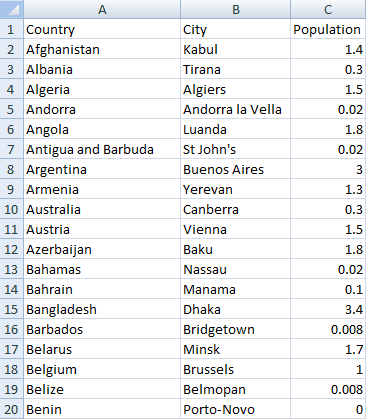
Once you are done parsing your data, I suggest copying and pasting it as values. This ensures you are not dependent on the original data. Once you have done that you can also eliminate any blank values in the Country, City, or Population fields. This will allow you to have an unbroken data set that you can easily filter or use in a pivot table. My completed data set after these changes looks like this:
The key thing to remember is that the original data needs some consistency in it before you can use a formula to be applied to it. If there is no consistency or has a lot variations to it, the more complicated your formula would need to be to pull what you need from it. In those situations, I prefer to use Visual Basic just because of the complexity that may be involved. This data set was fairly consistent and still involved some long, complex formulas to extract data from it.