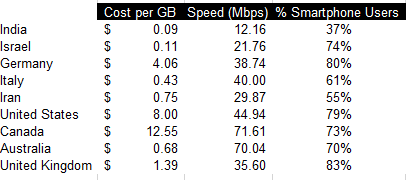
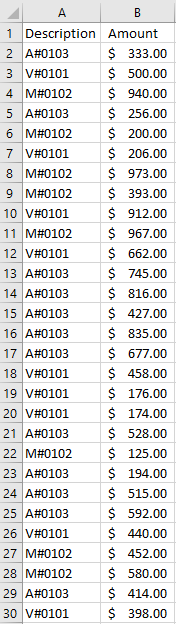
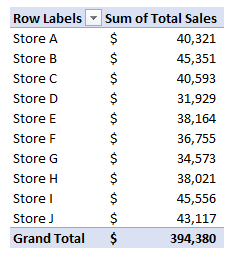
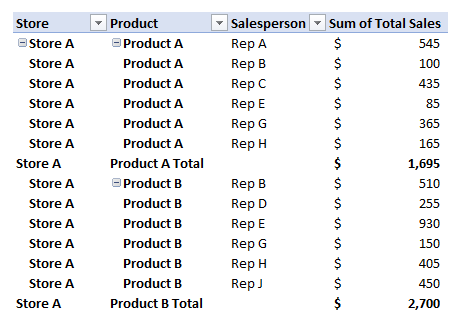
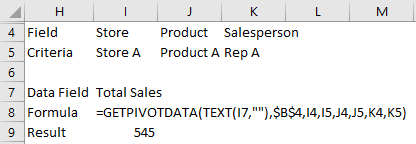
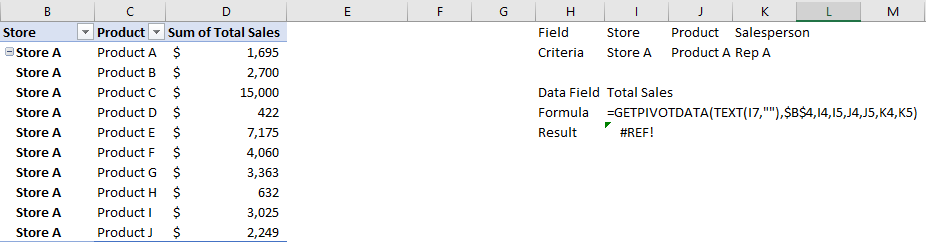
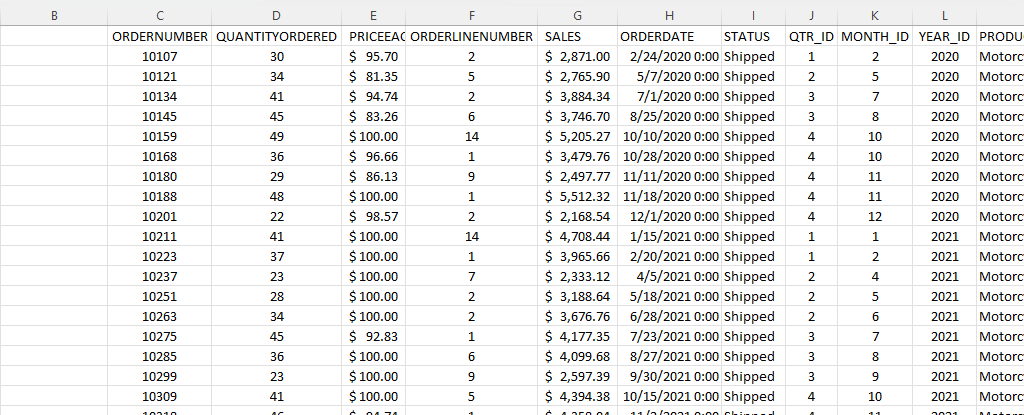
If you’re an accountant, you know that working with large amounts of data can be a daunting task. But with Excel, that work can get a whole lot easier and more efficient. Understanding Excel’s advanced features and functions can improve productivity, reduce errors, make your work more accurate, and most importantly — save you time. Below, I’ll go over some of the most important Excel functions that accountants should know, and provide examples of how to use them. For this example, I’ll use the following spreadsheet. Feel free to download it and follow along with the calculations.
1. SUM
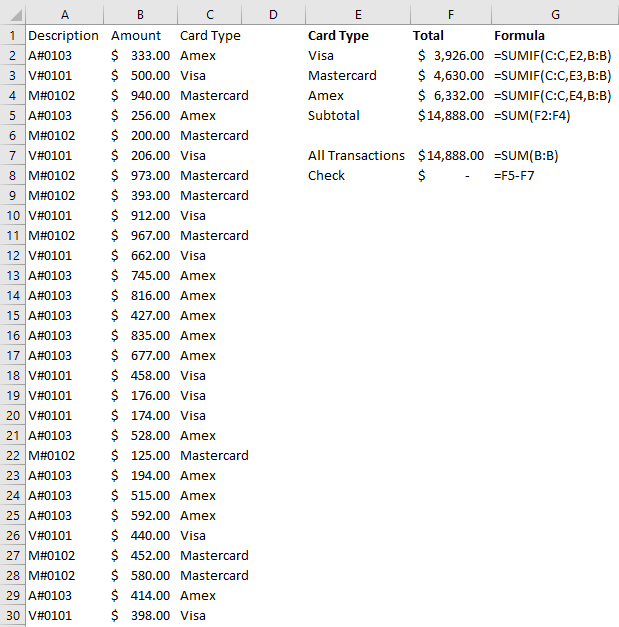
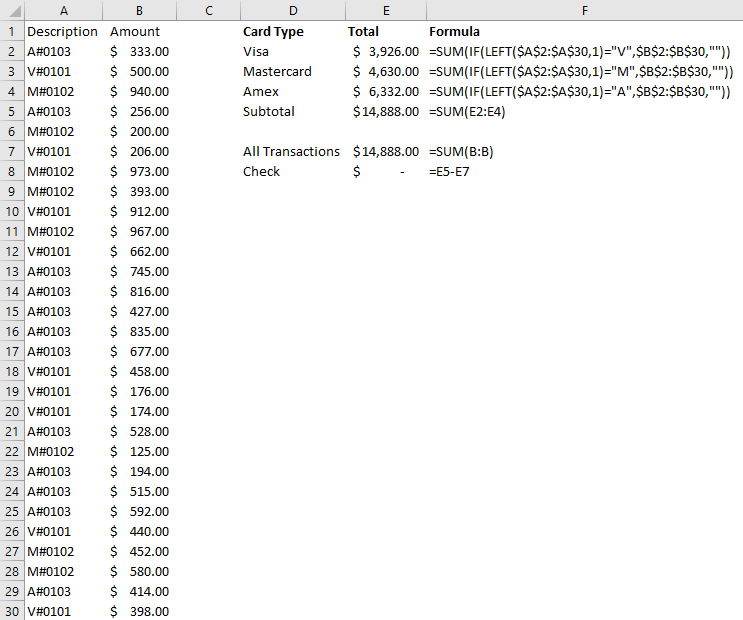
The SUM function is a basic but essential function in Excel. It allows you to add up a range of values, which is helpful when calculating totals, such as revenue, expenses, and profits. Suppose you have a spreadsheet with sales data. In the above example, the total sales are in column G. If you wanted to sum up the entire column, the formula would be as follows: =SUM(G:G)
2. AVERAGE
The AVERAGE function calculates the average of a range of values. It is useful when analyzing data and preparing financial statements. In the above example, suppose you wanted to calculate what the average sale was. To do this, you can just use the AVERAGE function on column G, similar to the SUM function before. Here’s the formula: =AVERAGE(G:G)
3. IF
The IF function allows you to test a condition and return one value if the condition is true and another value if the condition is false. This can be useful because it can send your formulas to the next level. By knowing to use the IF function, you could also use SUMIF, AVERAGEIF, and many other functions that involve an if statement. In the above example, let’s say you only wanted to know if a value in cell M2 was part of the Motorcycles product line. The formula would be as follows: =IF(M2=”Motorcycles”,1,2). If it is part of Motorcycles, you would have a value of 1, otherwise, it would be 2.
4. SUMIF
By knowing the SUM and IF functions, you can combine them together with SUMIF, which is an incredibly popular function. It gives you a quick way to tally up the totals that meet a criteria. For example, let’s say you want all sales that relate to the Motorcycles category. The formula for that would be as follows: =SUMIF(M:M,”Motorcycles”,G:G). If the criteria is met in column M, then the formula will sum up the corresponding values in column G. There’s also the super-powered SUMIFS function, which allows you to combine multiple criteria.
5. EOMONTH
The EOMONTH function calculates the last day of the month for a specified number of months in the future or past. It is useful when working with data that is organized by date. For accountants, this can be useful when you’re calculating when something is due. Let’s say in this example, we need to calculate the date orders need to go out on, and that needs to be the end of the next month. Using the ORDERDATE field in column H, here’s how that calculation would look in the first cell, which would then be copied down for the rest: =EOMONTH(H2,1)
6. TODAY
The TODAY function is helpful for accountants in calculating deadlines and knowing how many days are remaining or past a certain date. Suppose that you wanted to know how many days have past since the ORDER DUE DATE that was calculated in the previous example. Rather than entering in a static date that every day you would need to change, you can just use the TODAY function. Here’s how a formula calculating the days since the deadline for the first cell would look like, assuming the due date is in column N: =TODAY()-N2. The next day you open up the workbook, the calculations will update to reflect the current date; there’s no need to make any changes. There are many more date calculations you can do in Excel.
7. FV
The FV function calculates the future value of an investment based on a fixed interest rate and a regular payment schedule. You can use it to calculate the future value of an investment or savings account. Let’s say that you wanted to save $10,000 per year and expect to earn a return of 5% per year on that investment. Using the FV calculation, you can do that with the following formula: =FV(0.05,5,-10000). If you don’t enter a negative for the payment amount, the formula will result in a negative value. You can also specify whether payments happen at the beginning of a period (1) or end (0 — this is the default) with the last argument in the function.
8. PV
The PV function lets you do the opposite and work backwards from a future value to the present. Knowing that the calculation in example 7 returns a value of $55,256.31, that can be used in the PV calculation to check our work: =PV(0.05,5,10000,-55256.31). The formula returns a value of 0, which is correct, as there was no starting value in the FV calculation.
9. PMT
The PMT function calculates the periodic payment required to pay off a loan with a fixed interest rate over a specified period. It is helpful when determining the monthly payments required to pay off a loan or mortgage. Let’s take the example of a mortgage payment where you need to pay down $500,000 over the period of 30 years, in monthly payments. At a 5% interest rate, here’s what the payment calculation would be: =PMT(0.05/12,12*30,-500000,0). Here again the ending value needs to be a negative to avoid a negative value in the result. And since the payments are monthly, the periods need to be multiplied by 12 and the interest rate is dividend by 12.
10. VLOOKUP
The VLOOKUP function allows you to search for a value in a table and return a corresponding value from another column in the same row. It’s one of the most common Excel functions because of how useful and easy to use it is. It is helpful when working with large data sets and performing data analysis. Let’s suppose in this example that you want to find the sales related to order number 10318. The formula for that calculation might look like this: =VLOOKUP(10318,C:G,5,FALSE). In a VLOOKUP function, you need to specify the column number you want to extract from, which is what the 5 represents. If you’re using Office 365, you can also use the newer, flashier XLOOKUP function. I put VLOOKUP on this list because it’ll work on older versions of Excel — XLOOKUP won’t.
11. INDEX
The INDEX function allows you to return a value from a data set by specifying the row and column number. It’s also helpful if you just want to return data from a single row or column. For example, the sales column is in column G. If I know the order number is on row 20 (which relates to order number 10318), this formula would do the same job as the VLOOKUP in the previous example: =INDEX(G:G,20,1).
12. MATCH
The MATCH function allows you to find the position of a value within a range of cells. Oftentimes, Excel users deploy a combination of INDEX and MATCH instead of VLOOKUP due to its limitation (e.g. VLOOKUP can’t extract values to the left of the lookup field). In the previous example, you had to specify the row belonging to the order number. But if you didn’t know it, you could use the MATCH function within the INDEX function. The MATCH function would look like this: =MATCH(10318,C:C,0). Placed within an INDEX function, it can replace the argument where in the previous example, we set a value of 20: =INDEX(G:G,MATCH(10318,C:C,0),1). By doing this, you have a more flexible version of the VLOOKUP function. You can also create dynamic formulas using INDEX and MATCH that use lookups for both the column and row.
13. COUNTIF
The COUNTIF function allows you to count the number of cells in a range that meet a specified condition. Let’s count the number of values in the data set that are Motorcycles. To do this, you would enter the following formula: =COUNTIF(M:M,”Motorcycles”).
14. COUNTA
The COUNTA function is similar to the previous function, except it only counts the number of non-empty cells. With no criteria, it is helpful to just the total number of values within a range. To calculate how many cells are in this data set, you can use the following formula: =COUNTA(C:C). If there are no gaps in data, then the result should be the same regardless of which column is used. And when combined with the UNIQUE function, you can have an easy way to count the number of unique values.
15. UNIQUE
The UNIQUE function returns a list of unique values within a range, and it’s a much easier method than the old-school way of extracting unique values. If you wanted to extract all the unique product lines in column M, you would enter the following formula: =UNIQUE(M:M). If, however, you just wanted to count the number of unique values, you could embed it within the COUNTA function as follows: =COUNTA(UNIQUE(M:M)). You can adjust your range if you don’t want to include the header.
This is just a sample of some of the useful Excel functions that accountants can utilize. If you are familiar with them, you’ll put yourself in a great position to improve the efficiency of your workflow and make your spreadsheets easier to use. Plus, you can confidently say that you are highly competent with Excel, which can make your resume more attractive and make you better suited for accounting jobs that require advanced Excel skills — and there are many of them that do!.
If you liked this post on 15 Excel Functions Accountants Should Know, please give this site a like on Facebook and also be sure to check out some of the many templates that we have available for download. You can also follow me on Twitter and YouTube. Also, please consider buying me a coffee if you find my website helpful and would like to support it.